잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→
현록의 기록저장소
[Lv5] 매칭 점수 본문
https://programmers.co.kr/learn/challenges
프로그래밍 강의 | 프로그래머스
기초부터 차근차근, 직접 코드를 작성해 보세요.
programmers.co.kr
문제 설명
매칭 점수
프렌즈 대학교 조교였던 제이지는 허드렛일만 시키는 네오 학과장님의 마수에서 벗어나, 카카오에 입사하게 되었다.
평소에 관심있어하던 검색에 마침 결원이 발생하여, 검색개발팀에 편입될 수 있었고, 대망의 첫 프로젝트를 맡게 되었다.
그 프로젝트는 검색어에 가장 잘 맞는 웹페이지를 보여주기 위해 아래와 같은 규칙으로 검색어에 대한 웹페이지의 매칭점수를 계산 하는 것이었다.
- 한 웹페이지에 대해서 기본점수, 외부 링크 수, 링크점수, 그리고 매칭점수를 구할 수 있다.
- 한 웹페이지의 기본점수는 해당 웹페이지의 텍스트 중, 검색어가 등장하는 횟수이다. (대소문자 무시)
- 한 웹페이지의 외부 링크 수는 해당 웹페이지에서 다른 외부 페이지로 연결된 링크의 개수이다.
- 한 웹페이지의 링크점수는 해당 웹페이지로 링크가 걸린 다른 웹페이지의 기본점수 ÷ 외부 링크 수의 총합이다.
- 한 웹페이지의 매칭점수는 기본점수와 링크점수의 합으로 계산한다.
예를 들어, 다음과 같이 A, B, C 세 개의 웹페이지가 있고, 검색어가 hi라고 하자.
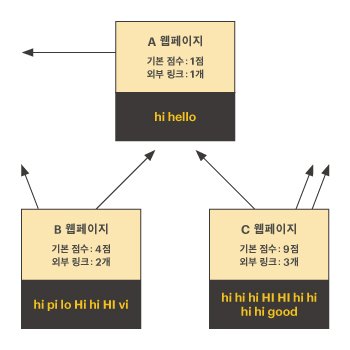
이때 A 웹페이지의 매칭점수는 다음과 같이 계산할 수 있다.
- 기본 점수는 각 웹페이지에서 hi가 등장한 횟수이다.
- A,B,C 웹페이지의 기본점수는 각각 1점, 4점, 9점이다.
- 외부 링크수는 다른 웹페이지로 링크가 걸린 개수이다.
- A,B,C 웹페이지의 외부 링크 수는 각각 1점, 2점, 3점이다.
- A 웹페이지로 링크가 걸린 페이지는 B와 C가 있다.
- A 웹페이지의 링크점수는 B의 링크점수 2점(4 ÷ 2)과 C의 링크점수 3점(9 ÷ 3)을 더한 5점이 된다.
- 그러므로, A 웹페이지의 매칭점수는 기본점수 1점 + 링크점수 5점 = 6점이 된다.
검색어 word와 웹페이지의 HTML 목록인 pages가 주어졌을 때, 매칭점수가 가장 높은 웹페이지의 index를 구하라. 만약 그런 웹페이지가 여러 개라면 그중 번호가 가장 작은 것을 구하라.
제한사항
- pages는 HTML 형식의 웹페이지가 문자열 형태로 들어있는 배열이고, 길이는 1 이상 20 이하이다.
- 한 웹페이지 문자열의 길이는 1 이상 1,500 이하이다.
- 웹페이지의 index는 pages 배열의 index와 같으며 0부터 시작한다.
- 한 웹페이지의 url은 HTML의 <head> 태그 내에 <meta> 태그의 값으로 주어진다.
- 예를들어, 아래와 같은 meta tag가 있으면 이 웹페이지의 url은 https://careers.kakao.com/index이다.
- <meta property=og:url content=https://careers.kakao.com/index />
- 한 웹페이지에서 모든 외부 링크는 <a href=https://careers.kakao.com/index>의 형태를 가진다.
- <a> 내에 다른 attribute가 주어지는 경우는 없으며 항상 href로 연결할 사이트의 url만 포함된다.
- 위의 경우에서 해당 웹페이지는 https://careers.kakao.com/index 로 외부링크를 가지고 있다고 볼 수 있다.
- 모든 url은 https:// 로만 시작한다.
- 검색어 word는 하나의 영어 단어로만 주어지며 알파벳 소문자와 대문자로만 이루어져 있다.
- word의 길이는 1 이상 12 이하이다.
- 검색어를 찾을 때, 대소문자 구분은 무시하고 찾는다.
- 예를들어 검색어가 blind일 때, HTML 내에 Blind라는 단어가 있거나, BLIND라는 단어가 있으면 두 경우 모두 해당된다.
- 검색어는 단어 단위로 비교하며, 단어와 완전히 일치하는 경우에만 기본 점수에 반영한다.
- 단어는 알파벳을 제외한 다른 모든 문자로 구분한다.
- 예를들어 검색어가 aba 일 때, abab abababa는 단어 단위로 일치하는게 없으니, 기본 점수는 0점이 된다.
- 만약 검색어가 aba 라면, aba@aba aba는 단어 단위로 세개가 일치하므로, 기본 점수는 3점이다.
- 결과를 돌려줄때, 동일한 매칭점수를 가진 웹페이지가 여러 개라면 그중 index 번호가 가장 작은 것를 리턴한다
- 즉, 웹페이지가 세개이고, 각각 매칭점수가 3,1,3 이라면 제일 적은 index 번호인 0을 리턴하면 된다.
입출력 예 #1
-
word : blind
-
pages :
["<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://a.com\"/>\n</head> \n<body>\nBlind Lorem Blind ipsum dolor Blind test sit amet, consectetur adipiscing elit. \n<a href=\"https://b.com\"> Link to b </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://b.com\"/>\n</head> \n<body>\nSuspendisse potenti. Vivamus venenatis tellus non turpis bibendum, \n<a href=\"https://a.com\"> Link to a </a>\nblind sed congue urna varius. Suspendisse feugiat nisl ligula, quis malesuada felis hendrerit ut.\n<a href=\"https://c.com\"> Link to c </a>\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://c.com\"/>\n</head> \n<body>\nUt condimentum urna at felis sodales rutrum. Sed dapibus cursus diam, non interdum nulla tempor nec. Phasellus rutrum enim at orci consectetu blind\n<a href=\"https://a.com\"> Link to a </a>\n</body>\n</html>"]
-
pages는 다음과 같이 3개의 웹페이지에 해당하는 HTML 문자열이 순서대로 들어있다.
Blind Lorem Blind ipsum dolor Blind test sit amet, consectetur adipiscing elit. Link to b
Suspendisse potenti. Vivamus venenatis tellus non turpis bibendum, Link to a blind sed congue urna varius. Suspendisse feugiat nisl ligula, quis malesuada felis hendrerit ut. Link to c
Ut condimentum urna at felis sodales rutrum. Sed dapibus cursus diam, non interdum nulla tempor nec. Phasellus rutrum enim at orci consectetu blind Link to a
위의 예를 가지고 각각의 점수를 계산해보자.
-
기본점수 및 외부 링크수는 아래와 같다.
- a.com의 기본점수는 3, 외부 링크 수는 1개
- b.com의 기본점수는 1, 외부 링크 수는 2개
- c.com의 기본점수는 1, 외부 링크 수는 1개
-
링크점수는 아래와 같다.
- a.com의 링크점수는 b.com으로부터 0.5점, c.com으로부터 1점
- b.com의 링크점수는 a.com으로부터 3점
- c.com의 링크점수는 b.com으로부터 0.5점
-
각 웹 페이지의 매칭 점수는 다음과 같다.
- a.com : 4.5 점
- b.com : 4 점
- c.com : 1.5 점
따라서 매칭점수가 제일 높은 첫번째 웹 페이지의 index인 0을 리턴 하면 된다.
입출력 예 #2
-
word : Muzi
-
pages :
["<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://careers.kakao.com/interview/list\"/>\n</head> \n<body>\n<a href=\"https://programmers.co.kr/learn/courses/4673\"></a>#!MuziMuzi!)jayg07con&&\n\n</body>\n</html>", "<html lang=\"ko\" xml:lang=\"ko\" xmlns=\"http://www.w3.org/1999/xhtml\">\n<head>\n <meta charset=\"utf-8\">\n <meta property=\"og:url\" content=\"https://www.kakaocorp.com\"/>\n</head> \n<body>\ncon%\tmuzI92apeach&2<a href=\"https://hashcode.co.kr/tos\"></a>\n\n\t^\n</body>\n</html>"]
-
pages는 다음과 같이 2개의 웹페이지에 해당하는 HTML 문자열이 순서대로 들어있다.
#!MuziMuzi!)jayg07con&&
con% muzI92apeach&2 ^
-
기본점수 및 외부 링크수는 아래와 같다.
- careers.kakao.com/interview/list 의 기본점수는 0, 외부 링크 수는 1개
- www.kakaocorp.com 의 기본점수는 1, 외부 링크 수는 1개
-
링크점수는 아래와 같다.
- careers.kakao.com/interview/list 의 링크점수는 0점
- www.kakaocorp.com 의 링크점수는 0점
-
각 웹 페이지의 매칭 점수는 다음과 같다.
- careers.kakao.com/interview/list : 0점
- www.kakaocorp.com : 1 점
따라서 매칭점수가 제일 높은 두번째 웹 페이지의 index인 1을 리턴 하면 된다.
필요한 정보: 자기 자신 url, 조건에 맞는 검색어 등장 수, 외부 url 수, 다른 페이지의 외부 url 중 자신을 가리키는 것이 있는가
자기 자신 url은 meta tag의 content="[url]" 로 되어있다고 한다.
정규표현식으로 <meta.* content=\"(https://.*)\".*/>로 뽑아올 예정.
meta 태그에 다른 attribute가 없다고는 안했으므로, .*으로 다른 attribute가 앞이나 뒤에 있어도 매칭되게 함.
(.:아무문자, *:0ormore)
조건에 맞는 검색어 등장 수 역시 정규표현식으로 가져올 예정.
외부 url 수는 a tag에 다른 attribute 없이 <a href="[url]"> 의 형식으로만 되어있다고 한다.
정규표현식으로 <a href=\"로 뽑아올 예정.
String[] urls = new String[pages.length];
String regex_url = "<meta.* content=\"(https://.*)\".*/>";
for(int i=0;i<pages.length;i++) {
Matcher m = Pattern.compile(regex_url).matcher(pages[i]);
m.find();
urls[i] = m.group(1);
}pages 배열을 돌면서 각각 자신의 url을 정규표현식으로 추출하여(m.group(1)) urls[]에 넣음.
String[] repages = pages.clone();
StringBuilder sb = new StringBuffer();
sb.append("(?i)(");
sb.append(word);
sb.append("[a-zA-Z]+|[a-zA-Z]+");
sb.append(word);
sb.append(")");
String regex_remove = sb.toString();
for(int i=0;i<pages.length;i++) {
repages[i] = repages[i].replaceAll(regex_remove, "");
}검색어는 단어는 대소문자 구별이 없지만 단어단위로 끊어져야한다고 했음.
word 도 되고, word@word2 등도 되지만,(알파벳이 아닌 모든 문자가 가능)
gword나 wordk처럼 바로 앞이나 뒤에 알파벳이 오면 안됨.
(?i): 대소문자 무시
+: 한 개이상
word[a-zA-Z]+
나
[a-zA-Z]+word
로 word 앞 뒤에 알파벳이 하나라도 붙은 애들은 그냥 ""로 지워버리고 시작함.
(검색을 위한 repage를 따로 복사해둠. 검색어 찾을 때만 지운걸 쓰면 다른데는 이상없음.)
int[] wordscore = new int[pages.length];
for(int i=0;i<wordscore.length;i++) {
int count = 0;
Matcher m = Pattern.compile("(?i)"+word).matcher(repages[i]);
while(m.find()) {
count++;
}
wordscore[i] = count;
}대소문자무시 word 단어가 나오면 숫자를 세서 wordscore[]에 각각 기본점수를 기록.
int[] outlink = new int[pages.length];
for(int i=0;i<outlink.length;i++) {
int count = 0;
String regex_a = "<a href=\"";
Matcher m = Pattern.compile(regex_a).matcher(pages[i]);
while(m.find()) {
count++;
}
outlink[i] = count;
}외부 url이 등장하는 숫자를 각각 outlink[]에 기록.
double[] matchingcore = new double[pages.length];
for(int i=0;i<matchingscore.length;i++) {
StringBuilder sb2 = new StringBuffer();
sb2.append("<a href=\"");
sb2.append(urls[i]);
sb2.append("\">");
String regex_tourl = sb2.toString();
for(int j=0;j<matchingscore.length;j++) {
if(i!=j) {
Matcher m = Pattern.compile(regex_tourl).matcher(pages[j]);
if(m.find()) {
matchingscore[i] += ((double)wordscore[j]/outlink[j]);
}
}
}
}외부 url 태그는 정확히 <a href="[url]">으로만 주어진다고 문제에 나왔었음.
매칭점수는 자신을 가리키는 다른 페이지들의 링크점수(기본점수(wordscore)/url태그수(outlink))들을 합하면 됩니다.
double[] totalscore = new double[pages.length];
for(int i=0;i<totalscore.length;i++) {
totalscore[i] = wordscore[i]+matchingscore[i];
}
double max = -1;
int answer = -1;
for(int i=0;i<totalscore.length;i++) {
if(totalscore[i]>max) {
max = totalscore[i];
answer = i;
}
}
return answer;total 스코어는 구해둔 자신의 기본점수(wordscore)에 매칭점수(matchingscore)를 합한 것.
가장 토탈스코어가 큰 index를 반환하면 끝.
'Problem Solving > programmers' 카테고리의 다른 글
| [Lv3] 가장 먼 노드 (0) | 2019.04.25 |
|---|---|
| [Lv5] 블록 게임 (0) | 2019.04.24 |
| [Lv5] 길 찾기 게임 (0) | 2019.04.24 |
| [Lv5] 무지의 먹방 라이브 (0) | 2019.04.24 |
| [Lv5] 실패율 (0) | 2019.04.24 |




잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→