잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→
현록의 기록저장소
RDB Modeling - 3. 개념적 데이터 모델링 본문
RDB Modeling (관계형 데이터베이스 모델링)
3. 개념적 데이터 모델링
3.1 - 개념적 데이터 모델링 소개
3.2 - 관계형 데이터베이스다운 개념의 구조
3.3 - ERD의 구성요소
3.4 - Entity 정의
3.5 - Attribute 정의
3.6 - Identifier 지정
3.7 - Entity간의 연결(Relationship)
3.8 - Cardinality
3.9 - Optionality
3.10 - ERD의 완성
3.11 - Entity Relationship Diagram Helper
(목차를 블록 선택 후, Ctrl+F로 탐색 가능 - 브라우저에 따라 다를 수 있음)
본 포스트는
생활코딩(https://opentutorials.org/)의
Database > 관계형 데이터 모델링(https://opentutorials.org/course/3883) 수업을 바탕으로
공부한 내용의 정리입니다.
<3.1 - 개념적 데이터 모델링 소개>
개념적 데이터 모델링이란
우리가 파악한 업무에서
개념을 뽑아내는 과정.
ㆁ일을 하는 순서와 공부를 하는 순서는 다를 수 있음.
*개념적 모델링이 논리적, 물리적 모델링보다 앞선 단계이지만,
ㆍ논리적, 물리적 모델링을 경험해보지 않은 사람이
개념적 모델링을 할 수는 없음.
ㆍ다음 단계를 위한 요소들을 추출해내는 과정이기 때문.
ㆍ관계형 데이터베이스 모델링의 가장 중요한 부분.
ㆍ첫 단추를 잘 꿰면 다음 수순이 물 흐르듯이 진행될 수 있음.
ㆁ개념적 데이터 모델링으로, 2가지의 선물과도 같은 효과를 볼 수 있음.
*필터: 현실에서 개념을 추출해내는 도구.
*언어: 개념에 대해 다른 사람들과 대화를 할 수 있는 도구.
*아래에서 보일 ERD가 바로 필터이자 언어로서의 도구이다.

ㆁEntity Relationship Diagram (ERD)
*개념적 데이터 모델링의 도구이자, 결과물.
*현실의 복잡성을 극복하고, 문제를 3개의 관점으로 본다.
ㆍ정보(●): 정보를 발견하고, 표현.
ㆍ그룹(■): 서로 연관된 정보를 인식하고 묶어서, 표현.
ㆍ관계(◆): 그룹 사이의 관계를 인식하고, 표현.
*현실로부터 개념을 인식하는 도구이면서, 다른 사람도 알 수 있도록 표현하는 도구.
*매우 쉽게 표(RDB diagram, 다음 단계인 논리적 모델링에서 작성)로 전환할 수 있음.
ㆍ오랜 시간 정교한 규칙들이 정립되어 왔음.
<3.2 - 관계형 데이터베이스다운 개념의 구조>
개념 추출
기획서에는 여러가지 정보들이 흩어져있음.
여기서 연관된 정보를 묶어주는 큰 덩어리부터 추출.
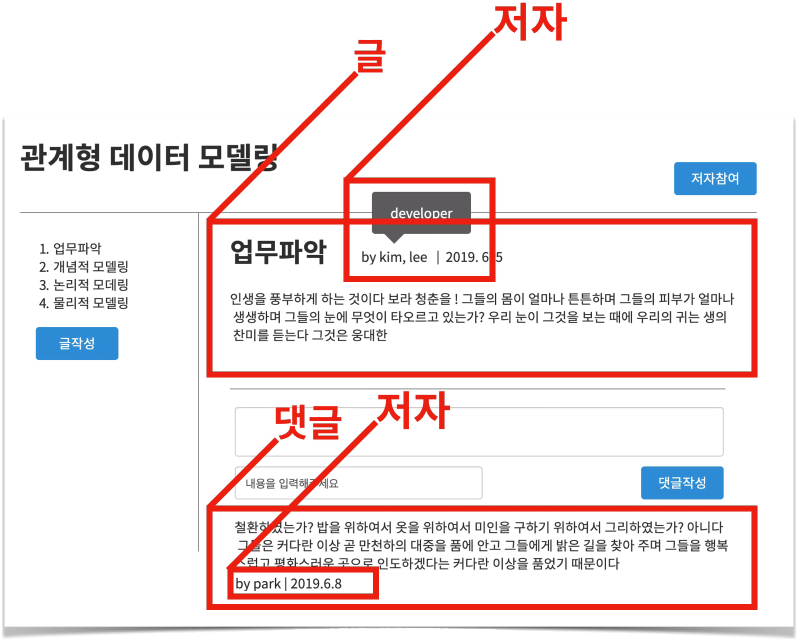
이제 이걸 어떻게 표현할지 정답은 없음.
설명이 가능하고 모순이 없다면 모두 타당.
하지만 필요한 정보는 모두 가져야 함.
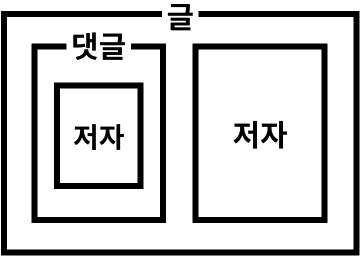

그 중에서
관계형 데이터베이스에 더 잘 어울리는 모델이 유리하므로,
두 번째 모델을 선택하겠음.
관계형 데이터베이스에 더 잘 어울리는 모델?
이 모델을 설명하기 위한 표를 생각해보자.

표 안에 작은 표가 내포(nested)되어 있는 형태.
그러나, RDB에서는 이러한 내포관계를 허용하지 않음.

보이도록 원하는대로 구현은 했지만,
개념들의 관계가 가시적으로 보이기 힘듦.
초거대 프로젝트라도 어떻게든 구현은 가능하겠지만,
알아보기 힘들고, 유지/보수도 힘듦.
(※ 예시는 약간 잘못되었음.
글에 다수의 저자가 참여가능하므로, "글 저자 ..."가 여러 개씩이어야 함.
여기서는 그냥 굉장히 복잡하게 "구현만을" 목표로 한 혼종을 이해하는 것으로.)
ㆁ프로젝트가 거대해지면, column이 1천개가 넘어질 수도 있음;;
*데이터를 원할 때, 1천개의 column에 access되므로 굉장히 비효율적임.
*굉장히 많은 중복 row가 발생할 수 있음. 당장 여기에서도 저자 1의 내용이 중복으로 저장되어 있음.
ㆍ저장 뿐 아니라, 입력, 수정도 중복으로 행해져야 함.
거대 단일 table로 표현하면, 중복이 발생함.
이제 이 모델을 설명하기 위한 표를 생각해보자.

*주제에 따라 data를 grouping할 수 있다.
*조회하려는 대상만 조회가능하므로, 컴퓨터의 자원을 아낄 수 있다.
*JOIN이 가능하다
ㆍSELECT 댓글.내용, 댓글.작성일, 저자.이름, 저자.소개 FROM 댓글 LEFT JOIN 저자 ON 댓글.저자아이디 = 저자.아이디

ㆍJOIN으로 표현이 가능하므로, 저장되는 데이터의 중복을 피할 수 있다.
ㆍ관계형 데이터베이스에서는 언제든지 필요할 때마다 표끼리 합성해낼 수 있음.
그러므로, 내포된 형태의 완성된 표가 아닌,
평면적인 형태의 개별적인 표를 서로 참조시켜서 사용한다.
<3.3 - ERD의 구성요소>
Entity(개념, 개체)
개념적 모델링 및 ERD에서,
이러한 모델의 구성요소(큰 덩어리)를
Entity라고 함.
이 Entity는 후에 Database에서 TABLE로 전환될 것임.
Entity 한 개를 가져와서 살펴보자.
Attribute(속성)

이 Entity는 실제 data는 아님.
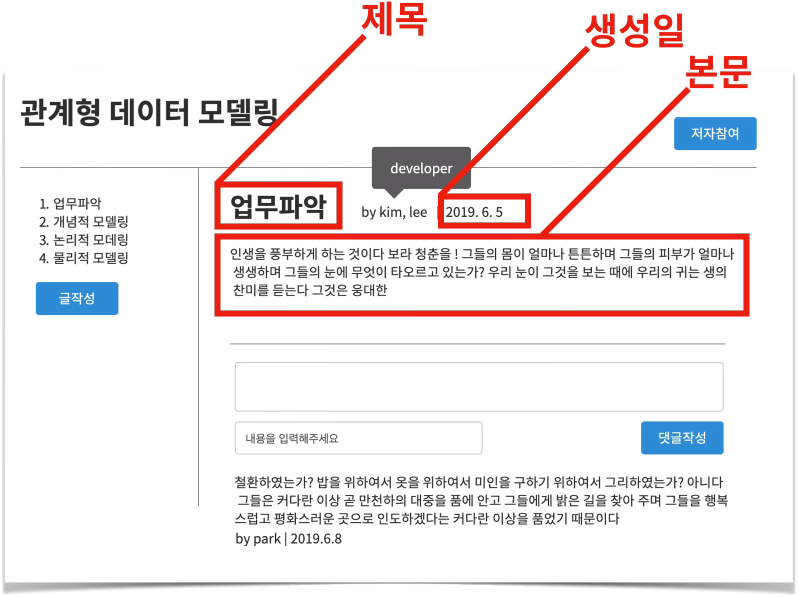
구체적인 data는 제목, 생성일, 본문, ...처럼
각 data들이 모여서 Entity를 이룸.

즉, 이러한 data를 grouping한 것이 Entity.
이 구체적인 data는 Attribute(속성)이라고 함.
Attribute는 후에 TABLE의 COLUMN이 됨.
그렇다면, 글에 있는
저자명, 댓글 등은 왜 글의 Attribute가 되지 않는가?
"저자명"만 필요하다면 Attribute가 될 수도 있음.
하지만, 저자명 외에 저자소개도 함께 필요함.
즉, 이러한 저자에 대한 data가 여럿이고, 이것들이 하나의 Entity가 됨.
Entity는 하위 Entity를 두지 않으며,
Entity는 개별적으로 존재(저장)하고,
필요할 때 JOIN을 통해 합한 결과를 이용할 것임.
그러므로, 모델링에서는 별개의 것으로 보면 됨.
Relationship(관계)
Entity들간의 관계.

글은 저자가 쓴 것.
글에 댓글이 포함되어 있음.
댓글은 저자가 쓴 것.
이러한 Entity 사이의 관계가 Relationship(관계).
논리적 데이터 모델링에서,
Entity에서 포함시키고 싶은 다른 Entity의 Primary Key(PK, 기본키)를
Foreign Key(FK, 외래키)로서 두고,
SQL문의 JOIN 기능을 이용하여
이 FK를 조건으로 하여, 일치하는 PK를 가진 data를
해당 Entity에서 참조하여 사용.
ERD의 구성요소
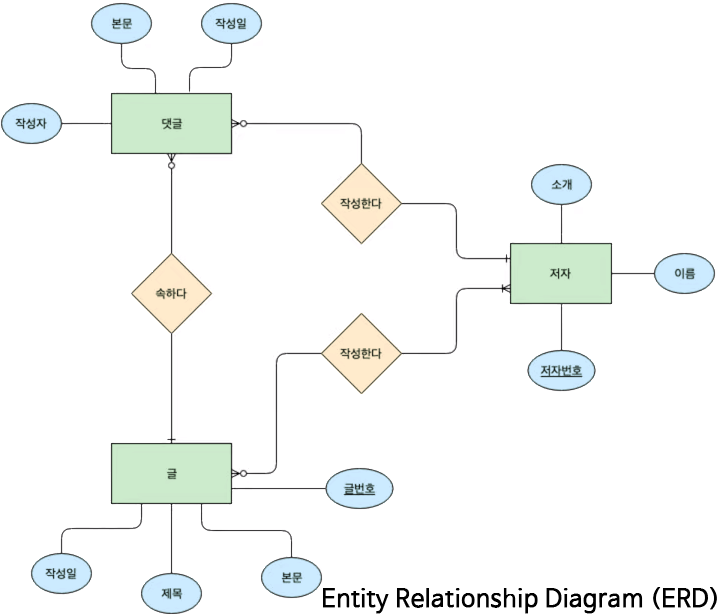
*Entity(■): data의 group
ㆍDatabase의 TABLE이 됨
*Attribute(●): data
ㆍTABLE의 COLUMN이 됨
*Relationship(◆): Entity간의 관계
ㆍTABLE의 COLUMN 중 Foreign Key(FK)로 다른 TABLE의 Primary Key(PK)가 올 것임
※ ERD에는 속하지 않지만,
표의 행(row)에 속하는 인스턴스인 Tuple이 있음.
(e.g., 30세 남성인 홍길동)
ㆍTABLE의 ROW가 됨
개념적 데이터 모델링은,
"개념"에 집중하여, Database 체계와는 거리를 두고 있기 때문에,
용어들이 실제 Database에서 사용하는 용어와는 다름.
<3.4 - Entity 정의>
현실과 data의 서로 원인-결과 관계
*Application을 하나의 건물이라고 할 때,
ㆍUI(User Interface)가 옥상이라면,
ㆍDB(Database)는 지하.
*UI와 DB 사이의 일들을 원인-결과의 관점으로 생각해보자.
ㆍUI에 data를 입력하는 원인으로, DB의 data를 변경하는 결과를 낳는다.
ㆍ또, DB의 data라는 원인으로, UI에 내용이 표시되는 결과를 낳는다.
즉, 사용자가 마주하는 UI(현실)와 컴퓨터(DB)에 저장되는 data는
서로 원인과 결과의 관계에 있다고 할 수 있다.
이 원인과 결과를 번갈아가면서 순차적으로 점검해야 좋은 모델링이 될 수 있다.
기획자와 구현자가 다르다면,
데이터 모델링까지는 함께 동행하는 것이 이상적이라고 생각함.
"기획"과 "데이터 모델링"은
사소한 부분까지 서로 놓치면 안되는 중요한 작업이다.
Entity 정의

가장 먼저 해야할 일은,
기획서에서 Entity를 찾아내는 것.
※ 팁으로, 읽기 UI보다는 쓰기 UI에서 Entity을 찾아내기 더 쉽다.

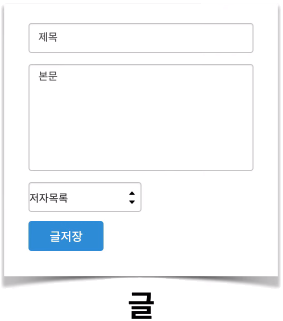
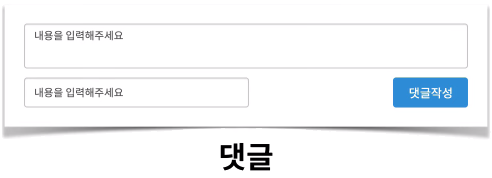
이제, 찾아낸 Entity를 토대로
ERD(Entity Relationship Diagram)을 작성해보자.
ERD에서의 Entity 표현
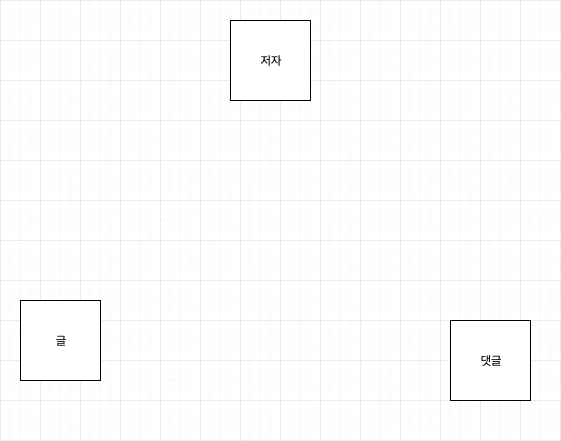
사각형에 Entity를 표현
<3.5 - Attribute 정의>
Attribute 정의
Attribute(속성)는 각 Entity의 소속이 될 data 종류.
역시 쓰기 UI에서 쉽게 파악할 수 있음.
※ 글 Entity에서,
"저자"가 Dropbox에서 선택하는 것은,
단독 data가 아니라 좀 더 복합적이라
별도의 Entity로 독립해 나가있을 수 있다는 것.
그래서 Attribute라기보다는, Relationship으로 연결.
쓰기 UI만으로는 부족한 정보가 있을 수 있음.
읽기 UI로 보면 글의 "생성일"이 보임.
쓰기 UI에서 별도의 지정없이 자동으로 현재 시각을 계산하여 포함되는 data.
이런 정보들도 빠뜨리지 않아야 함.
UI를 토대로 모델링을 하다보면,
UI가 모델링을 검증하고,
모델링이 UI를 검증하는
형태의 교차 점검이 이루어질 수 있음.
(기획에서 모델링으로 이어지고, 모델링하면서 부족했던 기획을 보충하고.)
그러므로, 기획자와 구현자가 한 사람이 아니라면(한 사람이면 best지만),
개념적 모델링까지는 함께 해야 좋은 결과를 얻을 수 있다.
ERD에서의 Attribute 표현

원에 Attribute 표현
<3.6 - Identifier 지정>
Identifier(식별자)
이제 Entity의 Attribute 중에,
대표자인 Identifier(식별자)를 뽑아야 함.
(Attribute들 중에 식별자가 될 수 있는 후보가 없다면 새로 추가해야 함)
(e.g., 국민의 주민등록번호, 자동차의 차량번호, 웹사이트의 도메인이름, ...)
원하는 대상(인스턴스. 개체)를 정확하게 가리킬 수 있어야 함.
중복될 수 없는 값을 가지기 때문에, 인스턴스간에 구분이 가능함.
즉, 그 대상을 제외한 누구도 같은 값을 가질 수 없는 것이 가장 중요.
이렇게 지정한 Identifier는
Database에서 Primary Key(PK, 기본키)가 될 것임.

ㆁname과 city는 중복이 발생할 수 있으므로 후보에서 제외한다.
ㆁuser_id, email, national_id는 각각 중복되지 않는 값을 가지므로,
Identifier의 후보가 될 수 있으며, 이들을 후보키(cadidate key)라고 한다.
*그 중 식별자로 지정한 것을 기본키(primary key)라고 한다.
*그 외 나머지 후보키는 대리키(alternate key)라고 한다.
ㆍ대리키는 필요한 때에, 성능 향상을 위해서 기본키가 아닌 secondary index로 지정하기 좋음.
복합키(composite key)
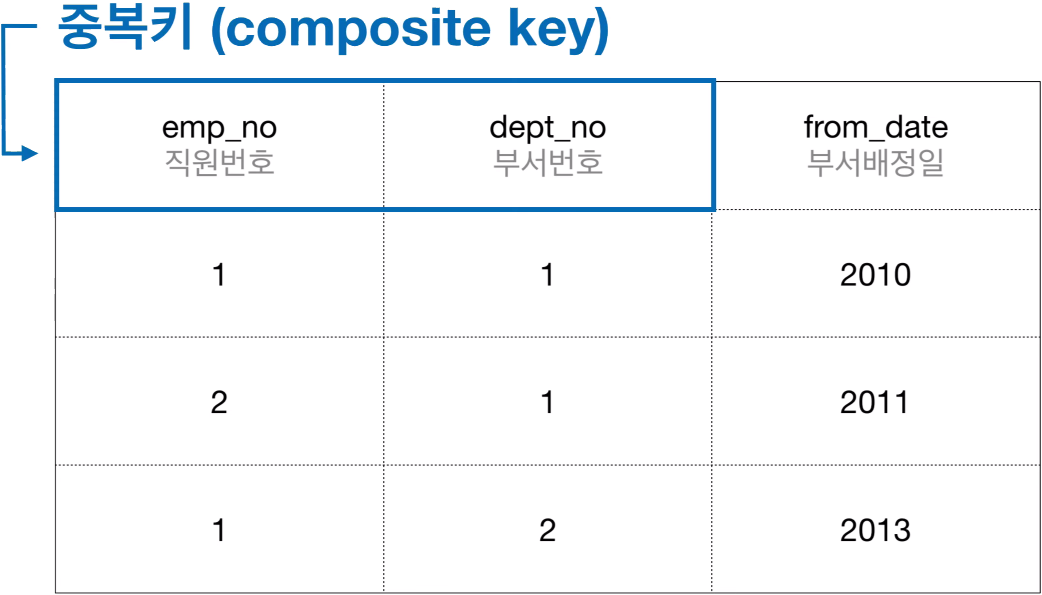
단일 Attribute로는 중복이 발생할 수 있지만,
여러 Attribute가 함께 사용된 결과는 중복이 발생할 수 없을 때(식별해낼 수 있을 때).
이 묶음 단위를 복합키(composite key)로 사용할 수 있다.
인조키(artificial key)
자연키(Natural Key)로는,
즉, 자연스럽게 존재하는 Attribute들로는 식별자를 선택할 수 없을 때,
인조키(Artificial Key)를 추가하여 사용.
※ Database에서는,
SEQUENCE를 생성하여 사용하거나(Oracle DB),
AUTO_INCREMENT 속성을 가진 INT를 사용하여(MySQL),
자동으로 1씩 증가하여 중복되지 않는 값이 매겨지도록.
ERD에서의 후보키 표시
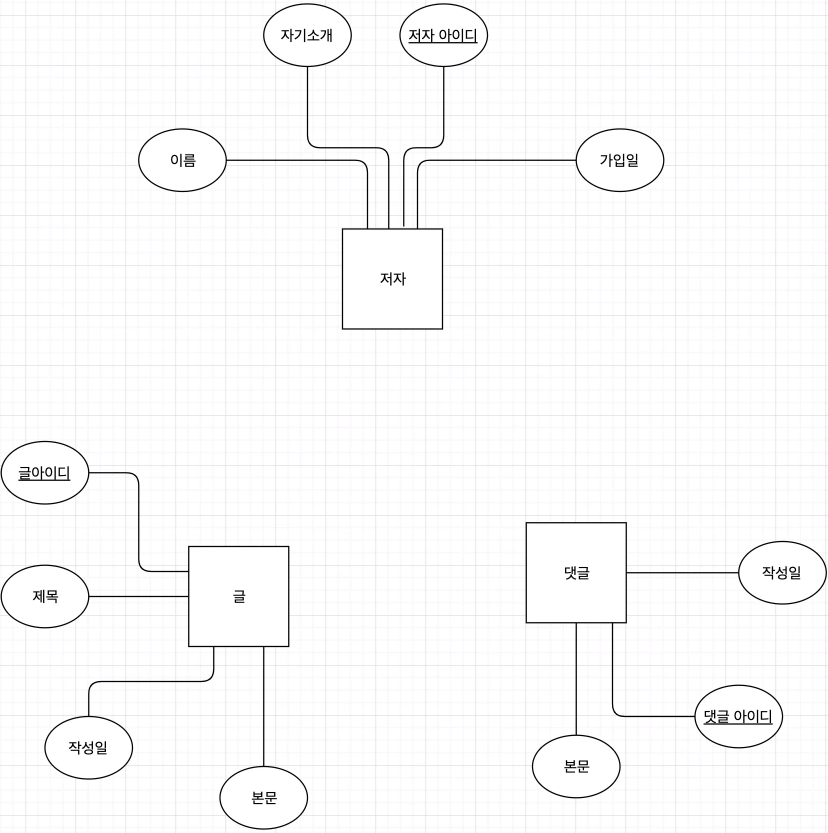
ERD에서는
식별자(기본키, PK)인 Attribute를
밑줄로 강조표시.
<3.7 - Entity간의 연결(Relationship)>
Relationship(관계)
각 표들이 연결된 형태.
이런 표들간의 관계.
외래(Foreign)에 있는 TABLE(e.g., 저자 TABLE)과 연결.
외래의 Primary Key(e.g. 저자.아이디)를 사용하여 저자의 특정 tuple(ROW)을
글 TABLE이나 댓글 TABLE에서 특정하여 가리킬 수 있으며,
이러한 외래의 식별자를 자기 TABLE(e.g., 글 TABLE, 댓글 TABLE)에서는
외래키(Foreign Key, FK)라고 한다.
즉, Database에서 Primary Key와 Foreign Key를 통해
Entity간의 Relationship이 구현된다.
ERD에서의 Relationship 표현
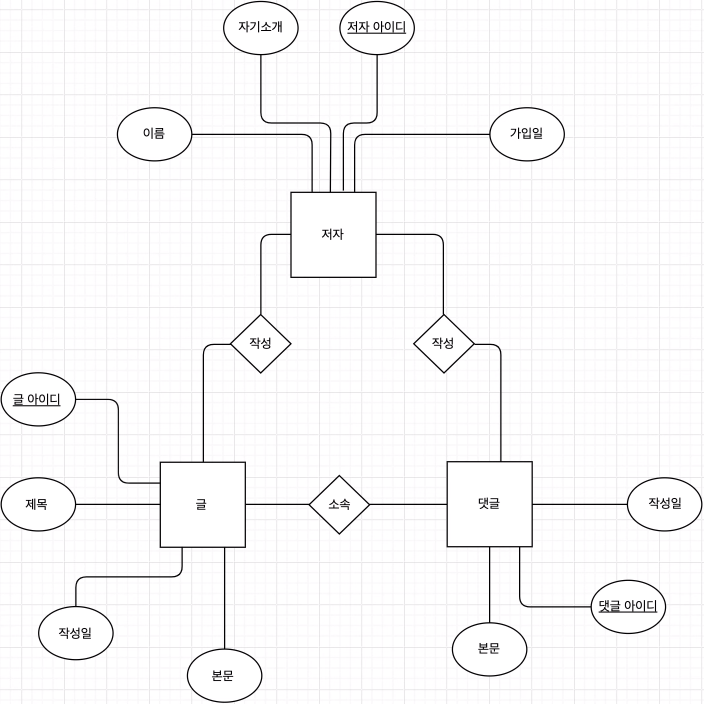
마름모 도형에 Relationship을 표현
※ 아직 Relationship의 주체, 대상, N:M 등을 표현하지 않았기에 완성형은 아님.
<3.8 - Cardinality>
Cardinality
집합론에서 집합의 "크기".
ㆁ가장 먼저 이해하기 쉬운 1:N 관계부터 보자.
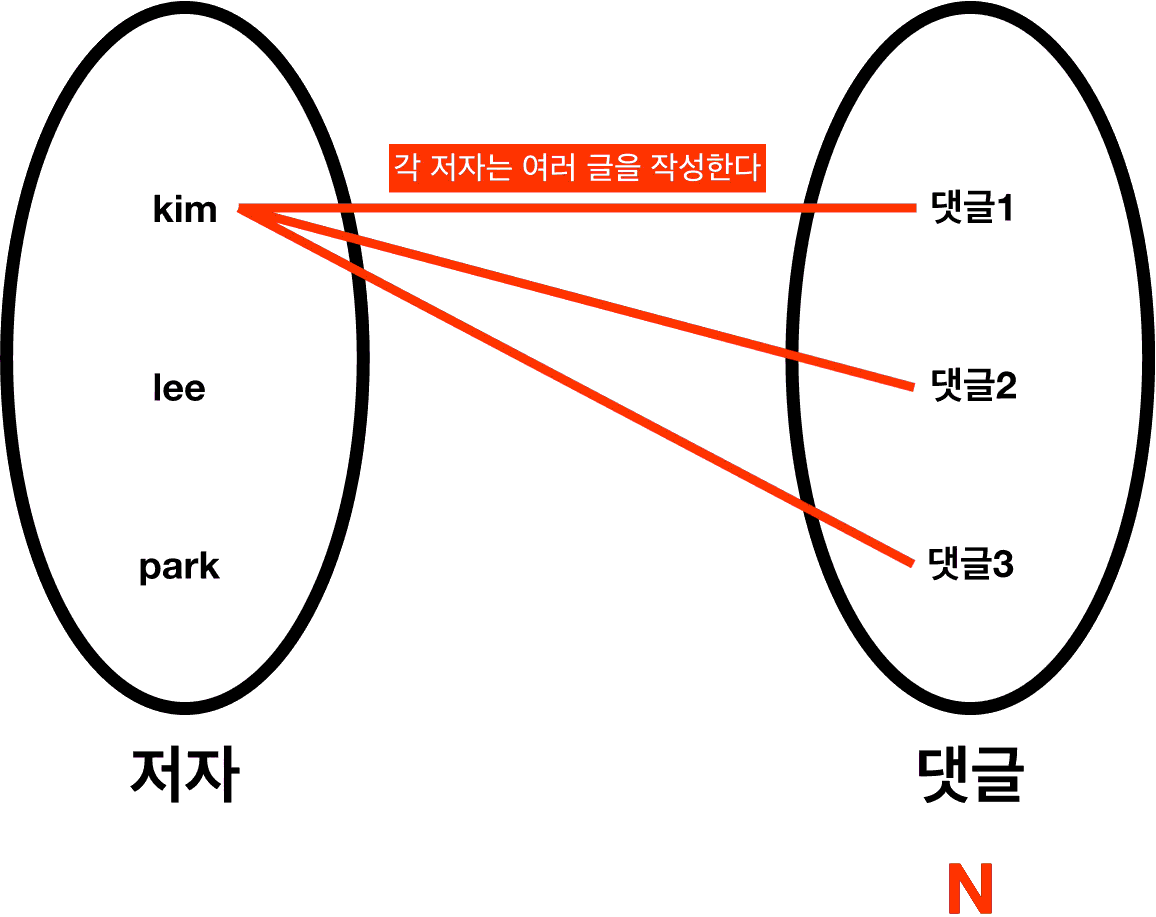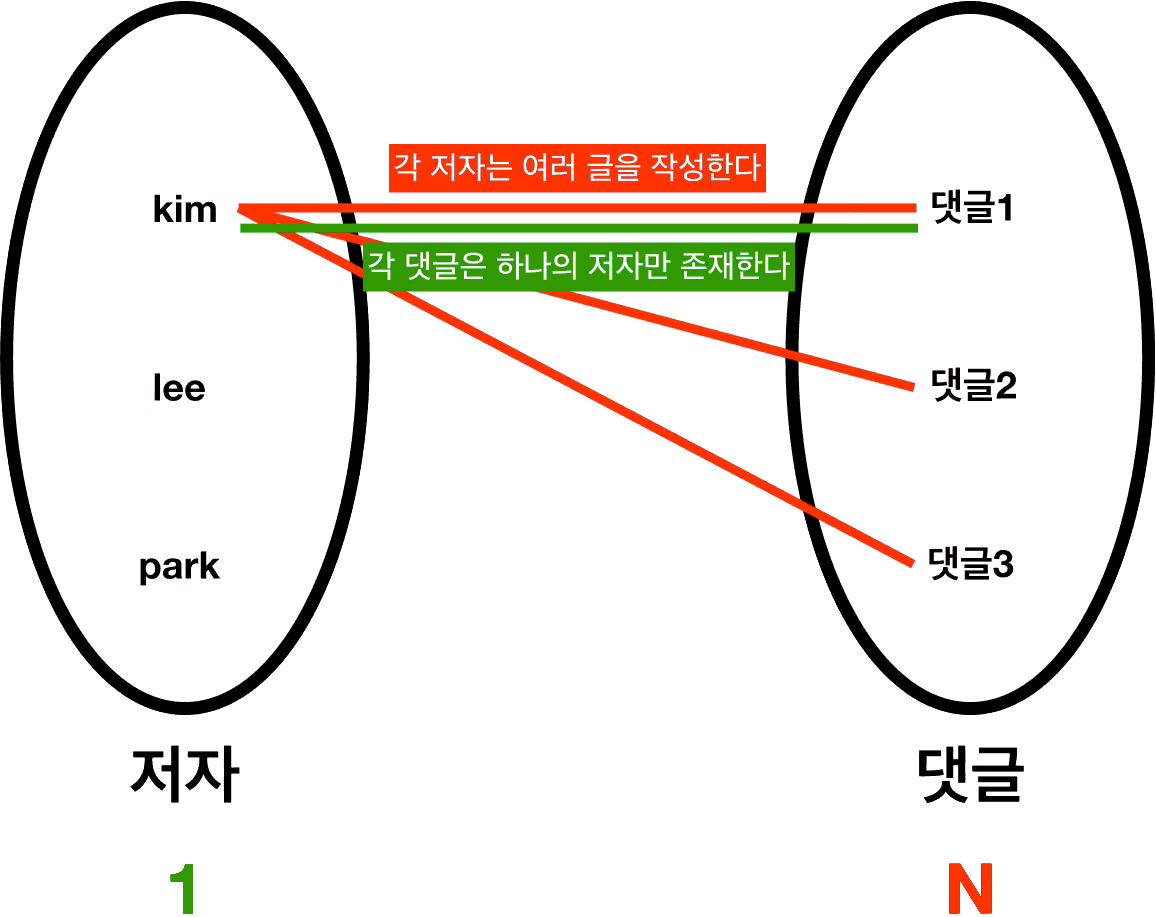
*"저자"의 입장에서, 댓글은 여러 개 가질 수 있다(한 명이 여러 댓글을 작성할 수 있다).
ㆍ?:N 관계가 된다.
*"댓글"의 입장에서, 저자는 하나 가질 수 있다(본 댓글은 한 명이 작성한 것이다).
ㆍ1:? 관계가 된다.
*합치면, 1:N의 관계가 된다.
*ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

ㆍ1인 쪽이 일직선, N인 쪽이 세갈래 선으로 표현된다.
ㆍ선의 끝에 1, N이라고 표시하기도 한다.
ㆁ다음으로, 1:1 관계를 보자.

*"담임"의 입장에서, 반은 하나 가질 수 있다(본 담임은 한 반만 담당할 수 있다).
ㆍ?:1 관계가 된다.
*"반"의 입장에서, 담임은 하나 가질 수 있다(본 반의 담임은 한 명만 될 수 있다).
ㆍ1:? 관계가 된다.
*합치면, 1:1의 관계가 된다.
*ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

ㆍ둘 다 1이라, 양쪽이 모두 일직선으로 표현된다.
ㆁ마지막으로, N:M 관계를 보자.

*"저자"의 입장에서, 글은 여러 개 가질 수 있다(한 명이 여러 글을 작성할 수 있다).
ㆍ?:M 관계가 된다.
*"글"의 입장에서, 저자는 여러 개 가질 수 있다(본 글은 여러 명이 작성했을 수 있다).
ㆍN:? 관계가 된다.
*합치면, N:M의 관계가 된다.
*ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

ㆍ둘 다 여러 개이므로, 양쪽이 모두 세갈래 선으로 표현된다.
ㆍ선의 끝에 N, M이라고 표시하기도 한다.
※ N:M의 경우,
Database의 TABLE끼리만으로는 표현이 불가능하기 때문에,
신규 TABLE에서 양쪽 TABLE의 FK를 사용하여 양쪽을 참조하는 형태(연결 TABLE)를 만들어서 사용.
즉, 연결 TABLE에서 1:N, 1:M으로 하여 구현.
<3.9 - Optionality>
Optionality
선택성.
ㆁ저자와 댓글의 예시를 다시 봅시다.
*"저자"의 입장에서, 댓글은 필수로 존재해야 하나요?
ㆍ아니요→Optional(선택적인)
*"댓글"의 입장에서, 저자는 필수로 존재해야 하나요?
ㆍ예→Madatory(필수적인)
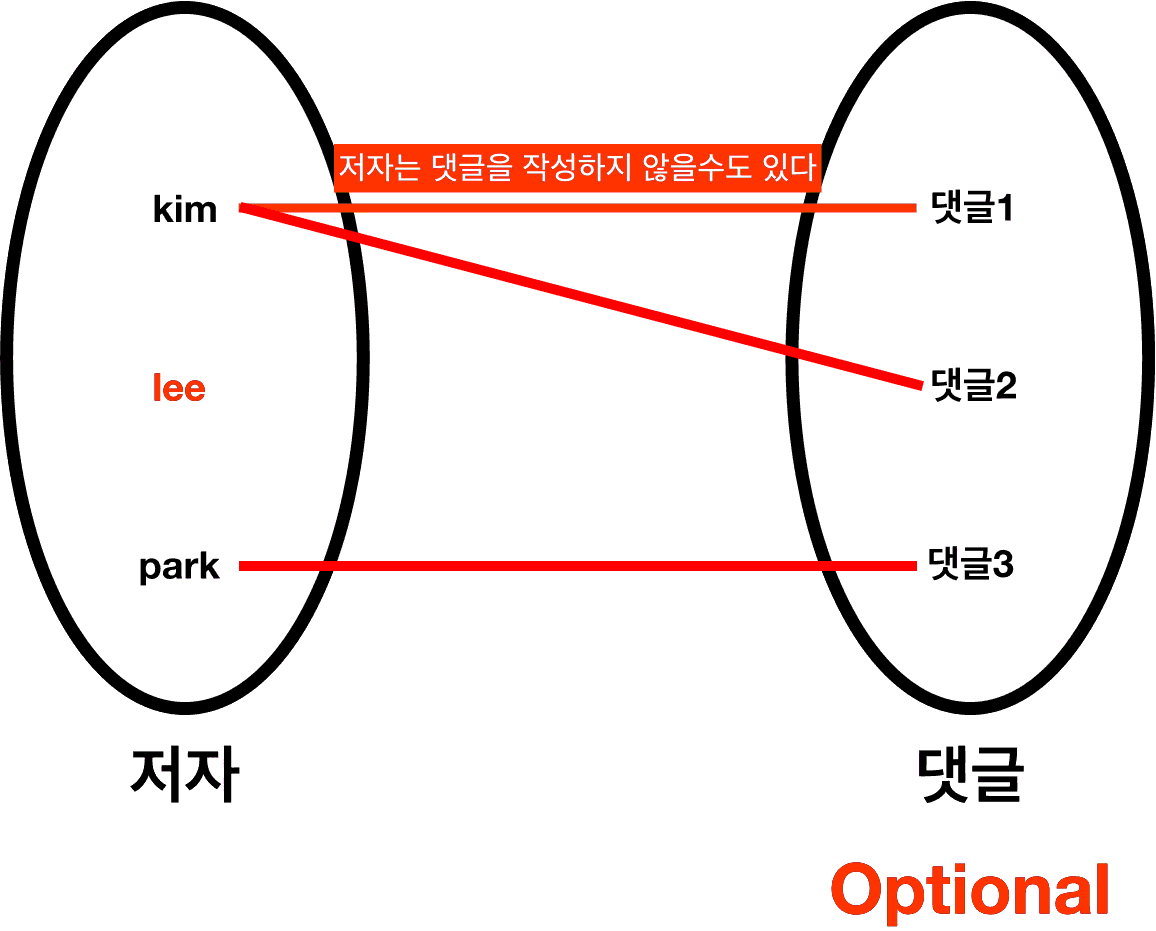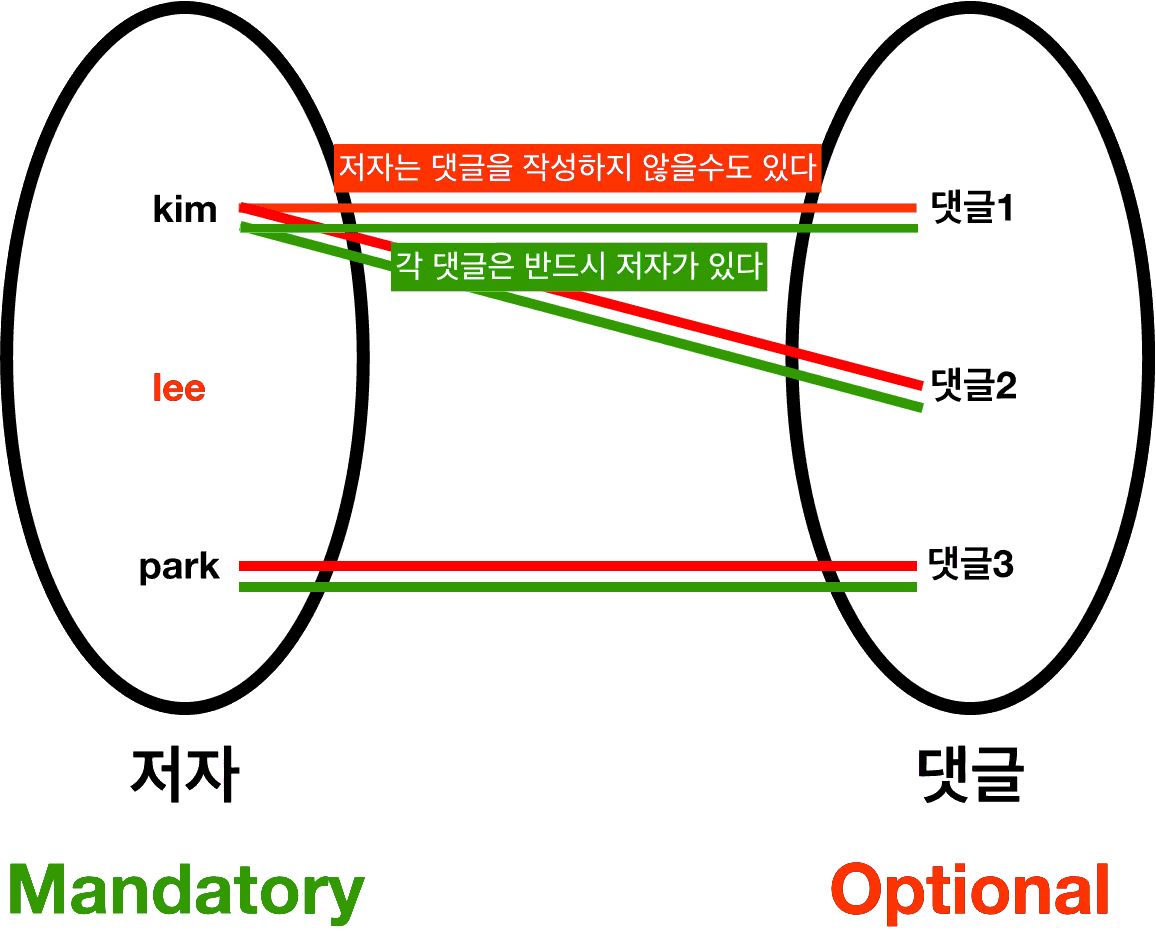
*ERD에서는 Relation의 양 끝이 다음과 같이 표현된다.

ㆍOptional인 부분에 원형이 매겨진다.
ㆍMadatory인 부분에 수직선이 매겨진다.
*기존 Cardinality 표현과 Optionality 표현이 합쳐진 완성본은 다음과 같을 수 있다.

※ Optinality는 Cardinality와 별개의 속성이다.
*Optionality는 개념에 따라 다를 수 있다.
ㆍEntity를 "선생님"으로 한다면, "반"은 Optional이지만,
ㆍEntity를 "담임선생님"으로 한다면, "반"은 Mandatory가 된다.
*Optionality는 현실에 따라 다를 수 있다.
ㆍ"학생" Entity와 "967회 모의 TOEIC 제출답안" Entity를 생각해보자.
ㆍ"제출답안" 입장에서는 "학생"은 하나만 가질 수 있고(본 제출답안의 작성자는 한 사람),
ㆍ"학생" 입장에서도 "특정 시험"의 "제출답안"은 하나만 가질 수 있다(여러번 칠 수 없고, 여러개 낼 수 없다).
ㆍ"제출답안" 입장에서는 존재하기 위해서 "학생"은 필수적이다(Mandatory).
ㆍ"학생" 입장에서는 시험을 치르지 않았을 수도 있다. "제출 답안"은 필수가 아니다(Optional).
ㆍCardinality는 1:1 관계이지만, 반드시 Mandatory:Mandatory로 이어지진 않는다.
*이렇게 현실에는 다양한 종류와 제약의 문제들이 존재한다.
<3.10 - ERD의 완성>
ERD에서의 Cardinality와 Optionality 표현

Relation의 양 끝에 알맞은 기호로 표현
모델링(개념적, 논리적, 물리적 모두) 과정에서
어떤 일을 해야하고,
어떤 기호를 써야하는가 등은
의견이 분분하고,
반드시 정해진 엄격한 룰이 있는 것은 아니니,
속한 곳 또는 일의 성격에 따라
작업의 순서를 바꾸거나 생략하거나 추가하기도 하니,
유연하게 대처.
<3.11 - Entity Relationship Diagram Helper>
'Study > Database' 카테고리의 다른 글
| RDB Modeling - 5. 정규화 (0) | 2020.01.03 |
|---|---|
| RDB Modeling - 4. 논리적 데이터 모델링 (0) | 2020.01.02 |
| RDB Modeling - 2. 업무파악 (0) | 2020.01.01 |
| RDB Modeling - 1. 데이터 모델링의 순서 (0) | 2020.01.01 |
| RDB Modeling (관계형 데이터베이스 모델링) (0) | 2020.01.01 |



잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→