잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→
현록의 기록저장소
컴퓨터 구조 및 설계 - Chapter 1. Computer Abstractions and Technology 본문
컴퓨터 구조 및 설계 - Chapter 1. Computer Abstractions and Technology
현록 2019. 11. 28. 13:24Chapter 1. Computer Abstractions and Technology
ㆍPerformance(성능)의 정의를 이해
1.1 - Introduction
1.2 - 8 Great Ideas in Computer Architecture
1.3 - Below Your Program
1.4 - Under the Covers
1.5 - Technologies for Building Processors and Memory
1.6 - Performance
1.7 - The Power Wall
1.8 - The Sea Change: The Switch from Uniprocessors to Multiprocessors
1.9 - Real Stuff: Benchmarking the Intel Core i7
1.10 - Fallacies and Pitfalls
1.11 - Concluding Remarks
(목차를 블록 선택 후, Ctrl+F로 탐색 가능 - 브라우저에 따라 다를 수 있음)
<1.1 - Introduction>
컴퓨터의 발전
*컴퓨터 기술의 진전
ㆍMoore의 법칙(반도체 집적회로의 성능이 2년마다 2배로 증가한다)
*새로운 응용 프로그램들이 실현 가능해짐
ㆍ자동차 내부의 컴퓨터
ㆍ스마트폰
ㆍ인간 게놈 프로젝트
ㆍWWW(World Wide Web), 웹 및 네트워크
ㆍ검색 엔진
*모든 것이 컴퓨터화 되고 있음
ㆍIoT 등.. 냉장고, 커피포트, ...
Moore's Law
1965년, Intel의 공동 설립자인 Gordon Moore가 제시한 것으로,
반도체 집적회로의 성능이 24개월(2년)마다 2배로 증가한다는 법칙.
(경험적인 관찰에 바탕을 두고서 한 말)
(2010년부터 점차 따라잡지 못하고 있으며 한계를 보인다고 함)
https://ko.wikipedia.org/wiki/%EB%AC%B4%EC%96%B4%EC%9D%98_%EB%B2%95%EC%B9%99
https://en.wikipedia.org/wiki/Moore%27s_law
컴퓨터의 종류
*개인용 컴퓨터(Personal Computers, PC)
ㆍ일반적인 용도, 다양한 소프트웨어.
ㆍ비용/성능이 다양함
*서버 컴퓨터(Server Computers)
ㆍ네트워크 기반
ㆍ높은 수용성(capacity), 성능(performance), 신뢰도(reliability)가 보장되어야 함.
그러므로 보통 고가, 대용량, 고성능.
ㆍ소형 서버부터 빌딩 사이즈의 규모까지 다양함.
*슈퍼 컴퓨터(Supercomputers)
ㆍ복잡한 과학적이나 공학적인 계산에 사용.
ㆍ초고성능이지만, 초고가, 전력소모, 유지비용 등의 비용문제가 있고, 그러므로 제한된 곳에서 사용됨.
*임베디드 컴퓨터(Embedded Computers)
ㆍEmbedded, 내장된. 즉, 시스템의 요소로서 구성되어 있음.
ㆍ제한된 전력,성능,메모리,비용에서 돌아갈 수 있도록 요구됨.
ㆍ항공 시스템이나 의료 시스템 뿐만 아니라, 스마트폰이나 태블릿 역시 임베디드 시스템이라고 할 수 있음.
잠깐상식, 컴퓨터 용량 단위
ㆍ1 Byte = 8 bits
ㆍKilobyte: 2^10 bytes = 1024 bytes
ㆍMegabyte: 2^20 bytes = 1024*1024 bytes
ㆍGigabyte: 2^30 bytes = 1024^3 bytes
ㆍTerabyte: 2^40 bytes = 1024^4 bytes
ㆍPetabyte: 2^50 bytes = 1024^5 bytes
ㆍExabyte: 2^60 bytes = 1024^6 bytes
PostPC 시대(PC 다음의 시대)

PC보다 스마트폰, 태블릿이 더 많이 팔리고 있으며,
스마트폰의 성장세가 꾸준히 상승 중.
*개인 모바일기기(Personal Mobile Device, PMD)
ㆍ배터리 사용
ㆍ인터넷 사용
ㆍ수십만~수백만원
ㆍ스마트폰, 태블릿, 워치, 글라스 등
*Cloud Computing
ㆍWarehouse Scale Computers(WSC).
컴퓨터를 사는 것이 아닌, 제공 업체에서 원하는 만큼 할당받음.
ㆍSoftware as a Sevice(SaaS).
소프트웨어는 서비스로 제공받을 수도 있음.
ㆍ기기에서의 실행과 클라우드에서의 실행이 나뉘어지기도 함.
복잡한 연산 등은 클라우드에서 행해지고, UI 등 필요한 부분만 클라이언트에서 실행되기도 함.
ㆍAmazon과 Google 등에서 서비스 중.
Chapter 1에서 어떤 것들을 배울 것인가
*어떻게 프로그램들이 기계 언어로 번역되어지는가
ㆍ그리고 하드웨어가 어떤 식으로 이런 명령들을 수행하는가
*하드웨어/소프트웨어 인터페이스
*무엇이 프로그램 성능을 결정짓는가
ㆍ그리고 성능은 어떻게 향상될 수 있는가
*하드웨어 디자이너는 어떻게 성능을 발전시킬 것인가
*병렬 프로세싱(parallel processing)이란
Performance(성능)를 이해해보자
*Algorithm(알고리듬)
ㆍ수행되는 연산(operation)의 수로 정의됨
*프로그래밍 언어, 컴파일러, 아키텍처(구조)
ㆍ연산(operation) 당 수행되는 기계 명령(machine instruction)의 수로 정의됨.
operation은 좀 더 추상화된 개념이고,
machine instruction은 CPU에서 수행되는 Assembly 수준의 명령처럼 좀 더 기계어 수준이라고 생각.
*프로세서와 메모리 시스템
ㆍ명령이 얼마나 빠르게 수행되는가로 정의됨
*I/O system (OS 포함)
ㆍInput/Output 작업이 얼마나 빠르게 수행되는가로 정의됨
<1.2 - 8 Great Ideas in Computer Architecture>
8 Great Ideas
컴퓨터의 성능향상에 지대한 공헌을 해 옴
ㆍMoore's Law을 위한 디자인
ㆍdesign을 간결화, 단순화하기 위해 추상적 개념(abstraction)를 사용
ㆍ공통되는, 일반적인 부분을 빠르게 할 것
ㆍparallelism을 통한 성능 향상
ㆍpipelining을 통한 성능 향상
ㆍprediction을 통한 성능 향상
ㆍ메모리의 체계
ㆍ여분(redundancy)을 통한 신뢰성(dependability) 향상 - 6장의 RAID와 관련
<1.3 - Below Your Program>
Below Your Program
Program에 대해 좀 더 자세히

ㆁApplication software: 일반적인 유저가 사용하는.
*high-level의 언어(C, C++, Java, ...)로 쓰여졌음
ㆁSystem software: 컴파일러나 OS처럼 기본적인.
*컴파일러: HLL(High-level Language) 코드를 기계어로 번역
*운영체제: 서비스 코드
ㆍinput/output을 조절
ㆍmemory와 storage를 관리
ㆍ작업(task)을 관리(scheduling), 자원을 공유(sharing resources)
ㆁHardware
*프로세서, 메모리, I/O controllers
Levels of Program Code

*High-Level language
ㆍ좀 더 추상화된 개념. 사람의 입장에서 쓰여지는 언어.
ㆍ생산성과 이식성을 향상시킴
*Assembly Language
ㆍ명령들(instructions)를 나타내는 문자표현(MOV ..., NOP, ...)
*Hardware representation
ㆍBinary digits (bits)
ㆍ명령(instruction)과 data를 뜻함
<1.4 - Under the Covers>
컴퓨터 내부로
Components of a Computer
컴퓨터의 구성요소
ㆁ모든 종류의 컴퓨터는 같은 요소들을 갖추고 있다.
*PC든, 서버든, 임베디드이든..
ㆁInput/Output을 갖추고 있음
*유저-인터페이스 기기
ㆍ디스플레이, 키보드, 마우스, ...
*저장소(Storage)
ㆍ하드디스크, CD/DVD, flash, ...
*네트워크 어댑터
ㆍ다른 컴퓨터와 통신
Touchscreen
*PostPC 장치들
*키보드와 마우스를 대체함
*Resistive(저항식)과 Capacitive(용량성)의 센서 타입이 있음
ㆍ대부분의 태블릿, 스마트폰은 Capacitive를 사용
ㆍCapacitive는 동시에 여러 손가락을 인식하는 멀티 터치를 사용가능
Through the Looking Glass

*Screen: 시각적 그림 요소(픽셀)
ㆍ픽셀당 연속되는 프레임 버퍼 메모리의 순서대로 화면에 보여지는 것으로 볼 수도 있음
(연속되는 픽셀들의 표현 집합으로 그림과 움직이는 그림을 표현)
Opening the Box

Capacative multitouch LCD Screen / 3.8V 25Wh battery / Computer board / ...

Inside the Processor (CPU)
*Datapath: 데이터의 작업을 수행
*Control: datapath 순서, memory, ... 들을 제어
*Cache memory
ㆍ데이터에 빠르게 접근하기 위한 작지만 고속의 SRAM 메모리

Abstractions(추상화)
: 복잡한 문제를 단순화하여 쉽게 풀 수 있도록 하는 기법
*Abstractions는 좀 더 유연할 수 있도록 도와준다.
ㆍlow-level의 복잡성을 줄여줌
*Instruction set architecture(ISA, 명령어 집합 구조)
ㆍ하드웨어/소프트웨어 인터페이스
소프트웨어는 instruction으로 구성되어 있고,
하드웨어는 이것을 실행. instruction을 통해 데이터를 교환.
*Application binary interface
ㆍThe ISA + system software 인터페이스
*구현
ㆍ기초적인 세부사항과 인터페이스
Data를 위한 안전한 장소
*휘발성 메인 메모리(Volatile main memory) - DRAM이 여기에 속함
ㆍ전원이 꺼지면 명령과 데이터를 손실함
*비휘발성 보조 메모리(Non-volatile secondary memory)
ㆍMagnetic disk(Hard-Disk Drive)
ㆍFlash memory(Solid-State Drive, Flash drive)
ㆍOptical disk(CD, DVD)
Network
ㆍCommunication, resource sharing, nonlocal access
ㆍLocal area network(LAN): Ethernet
ㆍWide area network(WAN): the Internet
ㆍWireless network: Wifi, bluetooth
<1.5 - Technologies for Building Processors and Memory>
기술 트렌드
*전자 기술은 계속해서 진화하고 있음
ㆍcapacity(수용력)와 성능(performance)는 증가하고 있음
ㆍcost(비용)은 감소하고 있음

| 년도 | 기술 | preformance/cost (성능/비용) |
| 1951 | 진공관(vacuum tube) | 1 |
| 1965 | 트랜지스터(transister) | 35 |
| 1975 | 집적 회로(Intergrated Circuit, IC) | 900 |
| 1995 | Very large scale IC (VLSI) | 2,400,000 |
| 2013 | Ultra large scale IC | 250,000,000,000 |
반도체(Semiconductor) 기술
*Silicon: 반도체(자유전자가 없어 부도체의 성능을 가지지만, 전자를 이동시키면 전류가 흐르는 도체의 성능을 가질 수 있음)
*성능을 변화시키기 위해 물질을 추가함(실리콘에 기판을 새겨넣음)
ㆍConductors(도체)
ㆍInsulators(부도체=절연체)
ㆍSwitch
집적 회로(Intergrated Circuit, IC)를 만드는 과정

실리콘 웨이퍼에 패턴을 입히고, 거기에 칩을 새김
※Yield(수율): 웨이퍼당 동작하는 기판의 비율
※Intel Core i7 Wafer는,
300mm wafer에 280개의 칩이 있고, 32nm 공정으로 새겨짐.
각 칩은 20.7*10.5mm.

<1.6 - Performance(성능)>
Defining Performance
어떤 것을 기준으로 성능이 좋다고 말할 수 있는가?
어떻게 정의하느냐에 따라 달라질 수 있음.
Response Time(응답시간)과 Throughput(처리량)
ㆁResponse Time(응답시간)
*하나의 task(작업)을 수행하는데 걸리는 시간
ㆁThroughput(처리량)
*단위 시간(unit time)당 얼마나 많은 일(work)을 할 수 있는가
ㆍe.g., tasks/transactions/... per hour
ㆁ응답시간과 처리량은 무엇에 영향을 받는가
*processor를 더 빠른 것으로 교체하면?
*더 많은 processor를 배치하면?
ㆍ같은 종류의 processor를 더 많이 배치해도
하나의 작업을 따로 나눠서 하진 않으므로
Response Time은 줄어들지 않지만,
같은 시간에 더 많은 일은 할 수 있을테니 Throughput은 늘어남.
ㆍ일반적으로 Response Time을 줄이면 Throughput도 늘어나지만,
Throughput을 늘린다고 Response Time도 줄어드는 것은 아님.
ㆁ우선 응답시간에 초점을 맞춰서 보자..
상대적인 성능(Relative Performance)
*성능의 정의 = 1/실행시간
*"A가 B보다 n배 더 빠르다"라는 것은,

*예시: 프로그램이 돌아가는데 걸리는 시간
ㆍA는 10초, B는 15초
ㆍExecution Time B / Execution Time A = 15s/10s = 1.5
ㆍ즉, A는 B보다 1.5배 더 빠르다.
실행시간 측정(Measuring Execution Time)
ㆁElapsed Time(경과 시간)
*모든 측면에서의 총 응답시간(response time). 어떤 작업의 시작부터 끝까지 총 작업시간.
ㆍProcessing, I/O, OS overhead, idle time(유휴 시간) 모두 포함
*System performance를 결정하는데 사용됨.
ㆁCPU Time
*주어진 일을 처리하는데 걸리는 시간(순수하게 CPU에서 걸리는 시간)
ㆍI/O이나 다른 작업을 하는데 사용된 시간을 제외
*user CPU time과 system CPU time이 있음
*프로그램이 다르면 CPU와 시스템 성능에 대해서도 다르게 영향을 받음
(프로그램마다 다르다,
어떤 프로그램은 CPU에 영향을 많이 받을 수도 있고,
어떤 프로그램은 시스템에 영향을 많이 받을 수도 있고..)
CPU Clocking

*Clock period: 한 클럭 싸이클 기간. rising edge 후 다음 rising edge까지(동일한 행동) 걸리는 시간.
ㆍ e.g., 250ps = 0.25ns = 250*10^-12 s
*Clock frequency(rate): 초당 싸이클 수
ㆍ e.g., 4.0GHz = 4000MHz = 4.0*10^9 Hz
리뷰: Machine Clock Rate
Clock rate(clock cycles per second in MHz or GHz)는 Clock period(Clock cycle time)의 반전이다.
CC = 1/CR
ㆍ10ns CC → 100MHz CR
ㆍ5ns CC → 200MHz CR
ㆍ2ns CC → 500MHz CR
ㆍ1ns CC → 1GHz CR
ㆍ500ps(0.5ns) CC → 2GHz CR
ㆍ250ps CC → 4GHz CR
ㆍ200ps CC → 5GHz CR
CPU Time

*성능은 다음으로 향상될 수 있다(CPU Time을 줄이기)
ㆍclock cycle의 수를 줄이면.
ㆍclock rate를 증가시키면.
ㆍ하드웨어 디자이너는 반드시 cycle 수 대비 clock rate를 조절해야한다.
(clock rate를 늘렸더니 clock cycle도 덩달아 올라가버린다거나,
clock cycle의 수를 줄였는데 clock rate도 덩달아 줄어든다거나..
중요한건 비율임)
CPU Time 예제
*컴퓨터 A: 2GHz clock, 10s CPU Time
*컴퓨터 B를 설계하면서..
ㆍ6s CPU Time을 목표로
ㆍ즉, 컴퓨터 A(10s) 보다 빠르도록 해야하는데,
B의 clock cycles는 A의 clock cycles의 1.2배이다.
*컴퓨터 B의 clock은 얼마나 빠르게 해야할까?

Instruction Count와 CPI

ㆁ프로그램의 Instruction 수(Instruction Count) 란?
*프로그램, ISA(Instruction set Architecture)와 컴파일러 등에 의해 결정됨
ㆁinstruction 당 평균 cycle 수 (Average cycles per instruction, CPI)
*CPU 하드웨어에 의해 결정됨(CPU가 어떻게 구성되어지고 만들어져 있는지에 따라)
*만약 instruction이 다르다면, CPI도 다름
ㆍinstruction이 섞여있으면, 평균 CPI를 산출해야 함
CPI 예제 1
ㆍ컴퓨터 A: Cycle Time = 250ps, CPI = 2.0
ㆍ컴퓨터 B: Cycle Time = 500ps, CPI = 1.2
ㆍ동일한 ISA (→같은 Instruction Count임)
ㆍ어떤 컴퓨터가 빠르며, 얼마나 빠른가?

CPI를 좀 더 자세히
ㆍ만약 instruction의 종류가 다르다면, 다른 cycle의 수를 요구함
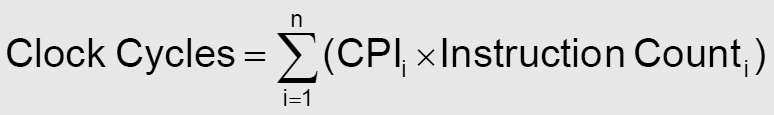
ㆍ가중 평균 CPI (weighted average CPI)

CPI 예제 2
*두 가지 다른 컴파일된 코드 결과를 처리하는데
아래와 같은 다른 세 종류의 CPU 혼합을 이용하였다.
| 종류 | A | B | C |
| CPI | 1 | 2 | 3 |
| 결과1에서의 Instruction 수 | 2 | 1 | 2 |
| 결과2에서의 Instruction 수 | 4 | 1 | 1 |
*결과1: Instruction 총 수 = 5
ㆍClock Cycles = 2*1 + 1*2 + 2*3 = 10
ㆍAvg. CPI = 10/5 = 2.0
*결과2: Instruction 총 수 = 6
ㆍClock Cycles = 4*1 + 1*2 + 1*3 = 9
ㆍAvg. CPI = 9/6 = 1.5
총 Instruction의 수는 결과2가 더 많았지만(6>5),
평균 CPI(Clocks per Instruction)는 결과2가 더 작았고, 결과1보다 더 빨리 실행이 될 수 있음.
Performance Summary

*성능은 다음에 의존한다
ㆍ알고리듬: IC에 영향, CPI에도 미칠 수도..
ㆍ프로그래밍 언어: IC, CPI에 영향
ㆍ컴파일러: IC, CPI에 영향
ㆍInstructions set architecture(ISA, 명령어 집합 구조): IC, CPI, Clock Cycle Time에 영향
예제
| Op | Freq | CPI_i | Freq * CPI_i |
| ALU | 50% | 1 | 0.5 |
| Load | 20% | 5 | 1.0 |
| Store | 10% | 3 | 0.3 |
| Branch | 20% | 2 | 0.4 |
| ∑ = 2.2 | |||
ㆍ더 좋은 데이터 캐시(평균 load time이 2 cycles로 감소된)를 사용하면 장치는 얼마나 더 빨라질 수 있겠는가?
→Load의 CPI_i가 5에서 2로 줄어들면,
Load의 Freq*CPI_i는 0.4가 되고,
모든 instruction의 Freq*CPI_i 합은 1.6으로 줄어든다.
2.2/1.6 = 1.375로, 기존의 1.375배의 속도가 된다. (37.5% 향상)
ㆍbranch prediction을 이용하여 branch time에서 한 cycle을 단축해보면 성능이 어떻게 될 것인가?
→Branch의 CPI_i가 2에서 1로 줄어들면,
Branch의 Freq*CPI_i는 0.2가 되고,
모든 instruction의 Freq*CPI_i 합은 2로 줄어든다.
2.2/2 = 1.1로, 기존의 1.1배의 속도가 된다. (10% 향상)
ㆍ두 개의 ALU 명령이 동시에 실행될 수 있다면 어떻게 될 것인가?
→ALU의 CPI_i가 1에서 0.5로 줄어들면,
ALU의 Freq*CPI_i는 0.25가 되고,
모든 instruction의 Freq*CPI_i 합은 1.95로 줄어든다.
2.2/1.95 = 1.1282로, 기존의 1.1282배의 속도가 된다. (12.82% 향상)
잠깐복습
Clock period의 정의는?
→Duration of a clock cycle.
Clock period ≡ Clock Cycle Time = 1 / Clock Rate
<1.7 The Power Wall>
※컴퓨터 구조 과목에서 Wall이란 단어를 두 군데에서 사용하는데,
한 군데가 Power, 한 군데가 Memory.
Power(전력)의 발전양상

*집적회로에서의 CMOS
ㆍCMOS의 첫 에너지 소비는 동적 에너지로, clock frequency마다 on-off, off-on으로 스위치 방식으로 제어된다.

그래프의 기간동안 전력소모는 약 30배 증가했으며, 전압은 5V에서 1V로, 주기는 약 1000배 빨라짐.
전압의 사용을 5V에서 1V로 낮추었기 때문에,
주기가 1000배나 빨라졌어도 전력소모는 약 30배 정도로 밖에 증가하지 않음.
반대로, 전력 소모를 더 이상 늘리지 않으려고 해서 Clock Rate의 성장 역시 멈춘 것으로 볼 수도 있음. (다음에 연속)
Reducing Power
전력소모를 줄여보자
*새로운 CPU가 있다고 가정해보자
ㆍ기존 CPU보다 85%의 capacitive load
ㆍ15%의 voltage 감소와 15%의 frequency 감소 (기존 CPU의 85% voltage, frequency)

*The Power wall
ㆍ그러나.. 더 이상 전압(voltage)을 감소시킬 순 없음..
ㆍ더 이상의 열(heat)을 잡을 수 없음(더 발열량이 늘어나면 안 됨)..
(전력소모가 많으면 열이 많이 발생함.. 전력소모는 늘어나선 안 되는데, 성능(frequency=clock rate)은 늘리고 싶고, voltage는 줄일 수 없고..)
*그러면 다른 방식으로는 성능을 향상시킬 수 없을까?
→Multi-core
<1.8 - The Sea Change: The Switch from Uniprocessors to Multiprocessors>
단일 프로세서에서 멀티프로세서로의 전환으로 흘러가고 있음
Uniprocessor Performance 단일 프로세서(Single-core) 성능

성능 증가는 계속 이루어지지만,
매년 52%의 성능 증가를 보였으나, 2003년을 기점으로 매년 22%의 성능 증가로 증가율은 떨어짐.
전력소모, instruction 수준의 병렬처리, 메모리 지연 등에 의한 제한이 성능 증가를 더디게 만들었음.
Multiprocessors
ㆁMulticore microprocessors
*칩 안에 여러 개의 processor를 탑재. multicore.
ㆁmulticore를 통한 성능향상을 보려면, parallel 프로그래밍이 필요함
(기존의 sequencial 프로그래밍으로는 multicore 환경에서의 이점(성능 향상)이 없음.
즉, 기존의 프로그램을 바꾸어야..)
*난관(Hard to do)
ㆍ성능을 위해 프로그래머가 일일이 parallel 프로그래밍을 해야함 (아래 등을 다 신경쓰면 기존(sequencial)보다 10배나 어려울 것 같음)
ㆍLoad balancing. 다수의 프로세서가 비슷한 양의 일을 나눠서 해야 효율적인데, 이 밸런스를 맞추는게..
ㆍcommunication과 synchronization 최적화
↕
※instruction 수준의 parallism(하드웨어가 알아서 명령을 동시에 실행)과 비교하면..
ㆍ하드웨어가 알아서 다수의 명령을 동시에 처리함
ㆍ프로그래머는 딱히 신경쓰지 않아도 됨
<1.9 - Real Stuff: Benchmarking the Intel Core i7>
SPEC CPU Benchmark
ㆁ성능 측정에 사용되는 프로그램
*실제 workload(작업량)만한 작업을 시켜서..
ㆁStandard Performance Evaluation Corp (SPEC)
*1988년 설립, 컴퓨터(CPU, I/O, Web, ...)에 대한 성능 벤치마크의 "표준화 된 세트를 생산, 확립, 유지 및 보증"하는 미국 비영리 단체.
https://en.wikipedia.org/wiki/Standard_Performance_Evaluation_Corporation
ㆁSPEC CPU2006
*선택한 여러 프로그램들을 실행하는데 총 경과된 시간
ㆍCPU에 집중된 프로그램들로, I/O는 무시할만한 수준으로 하여, CPU performance에 초점
(측정 자체가 CPU benchmark를 위한 CPU2006이니..)
*기준머신에 대하여 정규화 (기존에 기준으로 잡은 머신에 비해 얼마나 향상되었나를 보여줌)
*성능비(performance ratio)들의 기하 평균(geometric mean)으로 요약됨
ㆍCINT2006(integer)과 CFP2006(floating-point)

Intel core i7 920의 CINT2006

SPEC Power Benchmark
*다른 workload 수준들에서의 Server의 전력 소모
ㆍPerformance: Throughput(처리량)으로 측정됨. 초당 수행한 단위 작업의 수로 측정됨.
ssj_ops는, server side Java operations per second.
ㆍPower: Watts(W) (=J/s)

Xeon X5650의 SPEC power_ssj2008

ssj_ops / W의 단위가 클 수록,
전력 대비 많은 작업을 수행한 것이므로 클 수록 성능이 좋은 것(전력 효율).
<1.10 - Fallacies and Pitfalls>
Pitfall: Amdahl's Law
함정: Amdahl's Law (암달의 법칙)
https://ko.wikipedia.org/wiki/%EC%95%94%EB%8B%AC%EC%9D%98_%EB%B2%95%EC%B9%99
https://en.wikipedia.org/wiki/Amdahl%27s_law
*컴퓨터의 어떤 부분을 향상시키면, 전체적인 성능에서도 비례적인 향상을 기대할 수 있다.

ㆍ어떤 시스템을 개선하여
전체 작업 중 P%의 부분에서 S배의 성능이 향상되었을 때,
전체 시스템에서 최대 성능 향상은 위와 같다.

ㆍ개선 후의 실행시간 = (개선에 의해 영향을 받는 실행 시간 / 성능 향상 비율) + 영향을 받지 않는 실행 시간
즉, 시스템의 한 부분의 성능을 향상시키면,
전체 시스템의 성능 향상은 해당 시스템이 차지하는 비율에 비례해서만큼만 향상된다.
*예제: 전체 100초 중 곱 연산은 80초가 소요됨
ㆍ곱 연산 성능을 얼마나 향상시켜야 전체 성능이 5배로 증가할 수 있을 것인가?
→ 20s = 80s / n + 20s?? 불가능!!
ㆍ곱 연산의 성능 향상만으로는 20s까지(5배까지) 증가시킬 순 없다..
*추론: 일반적인 경우(부분)을 빠르게 하면 전체적으로 빨라진다.
시스템의 성능 향상을 하고자 하면,
시스템에서 가장 많은 부분을 차지하는 부분을 향상시키는 것이 바람직하다.
Fallacy: Low Power at Idle
착오: 유휴 상태에선 저전력인가??
*위의 Power benchmark에서..
ㆍ100% load: 258W
ㆍ50% load: 170W (66% - 258W에 비해서)
ㆍ10% load: 121W (47% - 258W에 비해서)
→10%의 load임에도 전력소모는 10%가 아닌 47%나 사용함.
load와 전력소모는 비례하진 않음.
*Google data center
ㆍ보통 10% ~ 50% load
ㆍ100% load가 되는 때는 전체 시간 중 1%도 안 될 정도로 거의 없음
→load는 10% ~ 50%라도 전력 소모는 적지 않을 것.
*프로세서를 설계할 때 load에 비례한 전력 소모가 이뤄질 수 있도록 하는 것이 이상적.
(하지만 어려운 일. 기술의 발전이나 설계자의 숙제라고 할까..)
Fitfall: MIPS as a Peformance Metric
함정: 성능 지표로서의 MIPS
ㆁMIPS: Millions of Instructions per second (초당 몇백만개의 instruction들을 실행하는가)
예전에 성능의 지표로 쓰이기도 했으나, MIPS는 많은 오해를 불러올 수도 있음..
*다음의 맹점이 있다.
ㆍ컴퓨터마다 ISA(명령 집합 구조)는 다름
ㆍinstruction마다 복잡도가 다름.
어떤 명령은 한 cycle이지만, 어떤 명령은 여러 cycles..
즉, 명령마다 CPI가 다름.

*같은 CPU에서도 프로그램에 따라 CPI는 달라진다.
(CPI는 CPU에 의해서도 달라지지만, 프로그램에 의해서도 달라진다.)
→즉, MIPS는 하드웨어의 성능측정 단위라고 하기 어려움.
앞서 본 SPEC의 Benchmark를 사용하는 것이 더 정확함.
<1.11 - Concluding Remarks>
Concluding Remarks 끝맺으며
*Performance/cost는 증가하고 있다
ㆍ기술의 발전으로.. (Moore's Law)
*추상화의 계층적인 층 구조
ㆍ하드웨어, 소프트웨어 양 쪽 측면 모두
*Instruction set architecture(ISA, 명령 집합 구조)
ㆍ하드웨어/소프트웨어 사이의 데이터/명령 교환(interface)
*Execution time: 성능 측정에 최고의 도구
*Power(전력소모)는 줄이는 데 한계가 있으며, 성능 향상에 제한을 주는 요소이다.
ㆍ그러므로 이제 성능 향상을 위해 parallelism을 사용
*CPU Time = Instruction Count * CPI * Clock Cycle Time
*성능(Performance)는 실행시간(Execution Time)에 반비례.
ㆍ성능_A / 성능_B = 실행시간_B / 실행시간_A
'Study > Computer Science' 카테고리의 다른 글
| 컴퓨터 구조 및 설계 - Chapter 5. Large and Fast: Exploiting Memory Hierarchy (0) | 2019.12.24 |
|---|---|
| 컴퓨터 구조 및 설계 - Chapter 4. The Processor (6) | 2019.12.15 |
| 컴퓨터 구조 및 설계 - Chapter 3. Arithmetic for Computers (0) | 2019.12.13 |
| 컴퓨터 구조 및 설계 - Chapter 2. Instructions: Language of the Computer (5) | 2019.11.30 |
| 컴퓨터 구조 및 설계 - 하드웨어/소프트웨어 인터페이스 (0) | 2019.11.28 |




잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→