잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→
현록의 기록저장소
[Lv3] 디스크 컨트롤러 본문
https://programmers.co.kr/learn/challenges
프로그래밍 강의 | 프로그래머스
기초부터 차근차근, 직접 코드를 작성해 보세요.
programmers.co.kr
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청 - 1ms 시점에 9ms가 소요되는 B작업 요청 - 2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.

한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
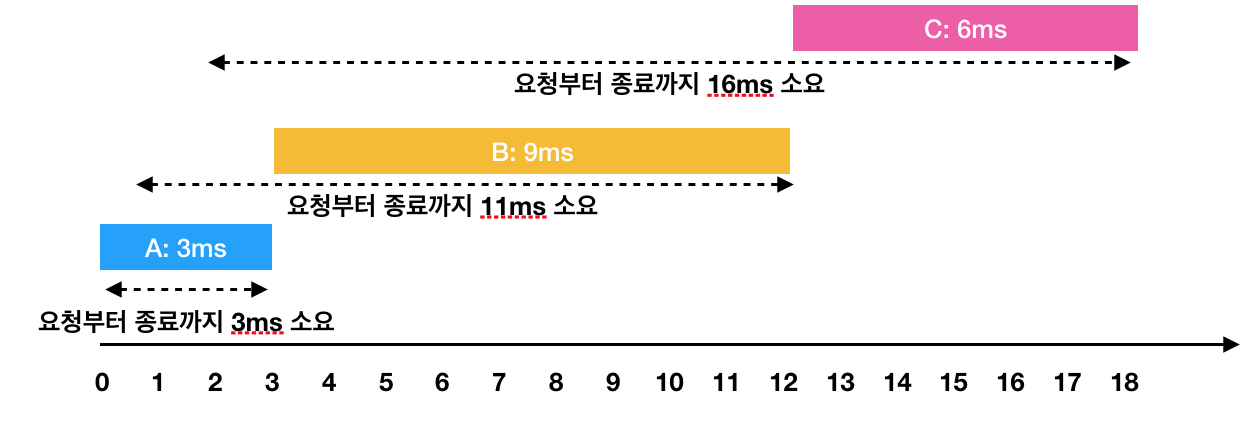
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms) - B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms) - C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면

- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms) - C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms) - B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예
| jobs | return |
| [[0, 3], [1, 9], [2, 6]] | 9 |
입출력 예 설명
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
시작하기 전에, 이 문제의 평균 합산법은 다음처럼 작동합니다.
(0,1,2), ..., (3,4,5)
처럼 0과2까지는 연속되게 동작하고, 한~참 뒤에(0~2까지 작업을 마치고도 유휴시간이 발생한 뒤에도) 3~5가 이뤄질 때,
0~2까지의 소요시간을 3개로 나누고,
3~5까지의 소요시간을 3개로 나누어 합해서 평균 작업시간을 구해야 할 것 같은데,
그냥 모든 소요시간을 6개로 나눕니다.
작업 덩어리 구획이 발생해도 나눌 숫자와 축적에 대해서는 신경쓰지 않아도 됩니다.
처음부터 끝까지 한 변수에 축적하고 마지막에는 그냥 총 갯수로 나누면 그만입니다.
Comparator<int[]> c1 = (a,b)->{
if(a[0]!=b[0]) return a[0]-b[0];
else return a[1]-b[1];
};
Arrays.sort(jobs, c1);
Comparator<int[]> c2 = (a,b)->{
return a[1]-b[1];
};
PriorityQueue<int[]> waiting = new PriorityQueue<>(c2);
int index = 0;
int end = 0;
int sum = 0;
while(index<jobs.length) {
end = jobs[index][0]+jobs[index][1];
sum += jobs[index][1];
index++;
while(index<jobs.length) {
if(jobs[index][0]<end) {
waiting.add(jobs[index]);
index++;
}
else break;
}
while(!waiting.isEmpty()) {
int[] shortest = waiting.poll();
sum += end-shortest[0]+shortest[1];
end += shortest[1];
while(index<jobs.length) {
if(jobs[index][0]<end) {
waiting.add(jobs[index]);
index++;
}
else break;
}
}
}
return sum/jobs.length;요청 작업들을 요청이 빠른 순으로, 요청이 같다면 소요시간이 적게 걸리는 애를 앞으로 오게 정렬합니다.
(긴 애는 혹시 다른 애가 치고 들어오면 대기시간이 발생할 수 있으니, 빨리 끝날 애부터 생각.)
끝날 시점(시작+기간) 전에 요청이 들어오는 다음 애들을 모두 우선순위 큐에 넣습니다.
이 큐는 작업시간이 적은 애가 앞에 오도록 합니다. 작업시간이 같다면 요청순서가 앞이든 뒤든 소요시간에 더해질 값은 같습니다.
큐에 있는 애들을 한번에 처리할 게 아니라 하나씩 계산합니다.
그래야 이번 애가 추가된 뒤로 다시 연장된 end까지 새로 들어올 애들(추가 while문에서 검사)에 대해서도 다시 연산이 가능합니다.
추가 while문에서는 추가되었던 애로 인해 새로 늘어난 end에 대해 검사하면서, 새로 큐에 넣게 될 애가 있는지 봅니다.
큐에 새로 들어오기도 하고, 합산에 넣어주면서 큐가 싹 비워졌다는건 하나의 겹치는 작업 덩어리 구획이 끝났다는 겁니다.
다음 루프로 넘어갈 때는 무조건 다음번 index의 애로 end와 sum을 계산하면 됩니다.(다음번 index가 없으면 계산 끝이겠죠.)
잘못된 정보가 있다면, 꼭 댓글로 알려주세요(비로그인 익명도 가능).
여러분의 피드백이 저와 방문자 모두를 올바른 정보로 인도할 수 있습니다.
감사합니다. -
후원해주실 분은 여기로→